Paper Review
Autonomous Human-Robot Interaction via Operator Imitation
- -
https://arxiv.org/pdf/2504.02724
https://arxiv.org/pdf/2501.05204
https://www.youtube.com/watch?v=4U4etupwzhQ
읽은 후 나의 평가
- 로봇 움직임, 강화학습이 답은 아니다 -> 강화학습보다는 생성모델
- HRI하는 로봇에 적용할 모델에 대해 지도학습이 나을 수 있다.
- 정교한 움직임을 요구하는 로봇이 아니라면 (반려로봇)이라면 로봇 운영자가 주어진 HRI 시나리오에 대해 자신이 생각하는
게임패드 조종을 기록하고 이를 지도학습 데이터셋으로 구축하여 생성 모델을 학습시키자 - Diffusion Policy 논문을 반드시 읽고 코드를 익혀야겠다.
Abstract
- 로봇은 운영자의 경험과 사회적 직관에 의존하여 인간과 표현력 있는 상호작용을 수행할 수 있음
- 본 연구에서 운영자 데이터를 모방하는 모델을 학습시켜 자율적인 상호작용 로봇을 만드는 방법을 제안
- 운영자의 로봇 제어를 통해 구축한 인간-로봇 상호작용 데이터셋을 모델에 학습시키며, 이 과정에서 운영자 명령어와 인간 및 로봇의 자세를 기록
- 해당 논문의 approach는
- diffusion process를 통해 연속적인 운영자 명령어를 예측하고
- classifier를 통해 이산적인 명령어를 예측하며,
- 이 모든 것이 단일 트랜스포머 아키텍처 내에서 통합
- 해당 방법이 expert-operator baseline에 필적하는 간단한 자율적 인간-로봇 상호작용을 가능하게 하며, 사용자들이 우리 모델에 의해 생성된 다양한 로봇 기분을 인식할 수 있음을 보여줍니다.
- 마지막으로, 동일한 운영자 인터페이스를 사용하는 ‘다른 로봇 플랫폼’에 우리 모델의 zero-shot transfer를 시연합니다.

[Fig. 1. Overview of our approach.]
- 우리는 먼저 remote operator(이미지에서 상단 빨간색)를 통해 human-robot interaction dataset을 수집합니다.
- motion control module은 operator commands를 입력받고 그것들을 robot actions에 매핑합니다. (이미지에서 중간)
- 우리는 그런다음 operator를 모방하는 diffusion-based model을 훈련시킵니다. (이미지에서 하단 왼쪽)
- 우리의 시스템은 사람과 간단한 interactions를 수행하고 서로 다른 기분을 표현하는것을 학습한다.
- 이미지에서 점선들은 data 수집을 위해 요청되는 요소 그리고 훈련을 위해 요구되는 요소들을 나타낸다

[Fig. 2. Our capture setup.]
- 운영자는 로봇을 제어하여 인간 참가자와 상호작용을 합니다.
- 인간과 로봇의 포즈, 그리고 운영자의 명령은 모션 캡처 스튜디오에서 기록됩니다.
I. Introduction
- 인간-로봇 상호작용(HRI)할때 숙련된 로봇 운영자가 로봇을 제어하는게 적합하다
- 왜냐하면, 로봇 운영자는 환경을 평가하고, 인간의 행동을 해석하며, 효과적으로 적절한 상호작용을 할 수 있기 때문
- 따라서 주요 과제는 이러한 숙련된 로봇 운영자 없이, 로봇과 사람이 자율적으로 HRI를 달성하는 것
- 운영자가 '자신의 경험과 인간의 움직임'과 같은 단순한 사회적 신호를 통해 로봇이 표현력 있고 생생한 행동을 표현할 수 있음
- 예를 들어, 수줍음을 타는 로봇은 안전한 거리를 유지하면서 바닥을 향해 보며 인간을 따라갈 수 있고,
즐거운 로봇은 인간 바로 뒤에서 가까이 달리며 때때로 춤추는 동작을 하게 할 수 있음 - -> 이것은 로봇 운영자가 자신이 판단해서 표현하는 것임
- 예를 들어, 수줍음을 타는 로봇은 안전한 거리를 유지하면서 바닥을 향해 보며 인간을 따라갈 수 있고,
- 이에 영감을 받아, 우리는 로봇이 robot-relative human pose를 통해 인간 상태를 근사화하여 접촉 없이 자율적으로 상호작용에 참여하고, 운영자와 비슷한 수준으로 다양한 기분을 표현할 수 있는 프레임워크를 개발하고자한다.
기존 방법의 한계
- 휴리스틱 기반 접근법[8], [9]은
- 확장성이 본질적으로 제한되고,
- expert knowledge가 필요하며,
- 각 로봇에 맞게 재정의해야 할 수 있음
- 강화 학습 접근법에서는
- 휴리스틱 기반 접근법과 마찬가지로 정책의 보상을 정의할 때에도 유사한 문제가 발생하며[10],
- 인간 동작을 현실적으로 시뮬레이션하는 어려움[11]이나 실제 환경에서의 긴 훈련 시간이 문제임
대안 제시
- 실제 세계 데이터를 수집하고 지도 학습 모델을 훈련하는 것
[해당 논문의 프레임워크 설명 구간]
본 연구에서 우리는 운영자를 모방하는 방법을 학습하는 HRI를 위한 새로운 프레임워크를 소개
외부 운영자가 로봇을 제어하여 인간과 상호작용하고 다양한 기분을 표현하는 인간-로봇 상호작용 데이터셋을 수집
- (이 데이터셋은 로봇과 인간의 자세와 함께 운영자의 원격조작 명령어를 포함)
중요한 점은 문제 정의가 로봇의 행동이 아닌 운영자를 모방하는 데 초점을 맞추어야함
- 이는 저수준 제어를 재학습하는 것보다 여러 이점이 있음
- 기존 모션 제어를 활용하면 로봇의 동역학과 관련된 복잡하고 데이터 집약적인 과정을 재학습할 필요가 없음
- 또한, 이는 로봇이 자신의 움직임 스타일, 견고성, 안전 제약을 유지하도록 보장함
우리의 방법에서는 diffusion model을 사용하여 운영자를 모방하고 다양한 상호작용을 예측
- 주로 연속적인 예측에 초점을 맞춘 이전의 motion diffusion framework[15], [16]와 달리,
- 우리는 게임패드 레이아웃에 맞게 연속적인 명령어와 이산적인 이벤트 모두를 예측할 수 있는 모델을 제안
- 연속 신호 예측을 위한 diffusion-based module과
- 이산 이벤트 예측을 위한 classifier를 통합하는
- unified transformer backbone으로 구성
- 우리 모델이 인간의 움직임에 동적으로 반응할 수 있도록 시간에 따라 변하는 robot-relative human pose를 조건으로 설정
- 그니깐 HRI를 이루기 위해 로봇 위치 중심(월드좌표계가 아닌)의 사용자 human pose를 입력받겠다는 의미
- 또한, zero input signals이 인간이 로봇에 가까이 있음을 나타내는 등의 유효한 입력일 수 있으므로, 인코딩 전이 아닌 후에 입력 신호를 마스킹하는 방법을 제안합니다[15].
[해당 논문의 실험 결과 및 평가 설명 구간]
- 우리의 실험은 1시간 미만의 데이터로, 우리의 프레임워크가 자율적인 상호작용을 수행하고, 여러 기분을 표현하며, 걷기와 서기와 같은 다양한 제어 모드 간에 전환하는 방법을 학습함을 보여줌
- 20명에게 우리의 시스템으로 로봇과 상호작용하게 하였는데, 자율적인 행동과 운영된 행동을 잘 구분하지 못하였음
- 또한, 사용자들이 로봇의 다양한 기분 쉽게 인식(이해)할 수 있었음
- 마지막으로, 우리는 비인간형 로봇으로 수집된 상호작용 데이터로 훈련된 모델의 zero-shot transfer를 humanoid 로봇에 시연하였음
[요약, 기여]
- 인간 운영자 데이터의 작은 데이터셋을 사용하여 간단한 자율적 인간-로봇 상호작용을 가능하게 하고 다양한 감정을 표현하는 새로운 시스템
- 인간의 자세를 기반으로 운영자 명령을 모방하고, 연속적 및 이산적 신호를 모두 예측하는 모델
- 우리의 모델이 현실적인 인간-로봇 상호작용을 생성하고 동일한 운영자 인터페이스를 사용하는 다양한 로봇 플랫폼에 전이된다는 시뮬레이션 및 실제 환경 실험을 통한 경험적 증거
II. RELATED WORK
우리는 related work를
- A. character control HRI와
- B. learning-based HRI로
나누었습니다.
A. Character Control
- Learning-based controllers는 시뮬레이션 및 실제 로봇 캐릭터 제어에서 뛰어난 성과를 보임.
- 크게 두 가지 유형으로 분류됨:
- 1. 모방 기반 제어기 (Imitation-based controllers)
- dense kinematic reference motions을 입력으로 사용.
- 관련 연구: [21], [22], [23], [24], [25]
- 2. 목표 지향 제어기 (Goal-driven controllers)
- 조이스틱 등 고수준 명령을 받아 캐릭터를 제어.
- 관련 연구: [4], [15], [26], [27]
- 1. 모방 기반 제어기 (Imitation-based controllers)
- 두 제어 방식은 종종 혼합되어 사용됨.
- 훈련 시에는 dense kinematic reference motions 사용.
- 실행 시에는 sparse user input만으로 제어 수행 [28].
Diffusion Models의 발전과 응용
- 최근 Diffusion 모델은 동작 생성(motion generation)과 제어에 활용됨 [16], [29].
- 대표 연구:
- CAMDM [15]
- 제어 신호를 기반으로 자동 회귀 방식의 키네마틱 동작 생성.
- RobotMDM [30]
- 사전 훈련된 제어기에 맞춰 동작 생성.
- CLoSD [31]
- 제어기를 생성 과정에 직접 통합.
- CAMDM [15]
- 우리 모델은 이러한 물리학 기반(physics-based) 접근 방식을 기반으로 하지만, dense references 대신 인간-로봇 상호작용을 위한 데이터 수집 중에 제공된 user inputs을 모방하는 방법을 채택함.
- → 데이터 요구를 줄이고 인간-로봇 상호작용에 특화된 방식.
인간-로봇 상호작용(HRI)에서의 Diffusion 모델 활용
- Yoneda et al. [32]:
- 공유 자율 시스템(shared autonomy) 제안.
- 사용자의 로봇 조작을 보조하는 에이전트를 확산 모델로 학습.
- Diffusion Co-Policy [33]:
- 협력적 테이블 운반 작업에서의 공동 제어 모델 제안.
- 본 논문은 이들과 달리:
- 2D 이상의 연속적 동작 공간을 다루며,
- 연속 동작과 이산 이벤트를 모두 예측 가능.
- 인간이 조작하는 로봇의 보조 시스템이 아니라,
- 로봇을 완전히 자율적으로 제어함.
B. Learning-Based Human-Robot Interactions
- 최근 deep learning 기반 기술을 활용한 자율 HRI(autonomous Human-Robot Interaction) 연구가 활발하게 진행됨.
- 대부분은 특정 과제에 특화된 단일 동작(task-specific, isolated behaviors)에 초점을 맞춤:
- Human-robot handshake: [34], [35]
- Human-robot handover: [36], [37]
- Table carrying: [38]
- 비학습 기반 방법까지 포함한 더 폭넓은 개요는 [5], [6] 참조.
physical human-robot interaction 중심의 학습 기반 접근
- physical HRI에서 학습 기반 접근법이 다수 제안됨.
- 일반적으로는 human-human interaction demonstrations(사람 간 시범)을 활용.
주요 연구 사례:
- Nikolaidis et al. [39]:
- 인간 행동을 클러스터링하고 사용자와 일치하는 로봇 정책을 학습하는 unsupervised learning 알고리즘 제안.
- [40]:
- 인간-로봇 상호작용을 latent space에서 표현하는 deep generative model (VAE 기반) 제안.
- [41], [42]:
- joint latent representation을 학습하여,
- human-robot hand interaction (사람이 다른 사람에게 컵을 손으로 건네주는 장면을 여러 번 녹화해서 데이터를 수집) 및 social motion forecasting 수행.
- Co-GAIL [43]:
- adversarial imitation learning을 통해
- 인간과 로봇의 정책(policy)을 동시에 진화시킴.
- [44]:
- multi-agent interaction을 위한 intent-aware latent representation을 도입.
본 연구와의 차이점
- 기존 연구들과 유사한 부분도 있지만, 본 논문의 기본 전제는 다름:
- human-human demonstrations를 사용하지 않음.
- 이유: 원격 조작 기반 로봇은 인간 해부학과 크게 달라
- 동작 간 직접적인 매핑이 어렵기 때문.
- 대부분의 기존 연구는 physical interaction 기반의 협업 작업에 집중.
- 반면 본 논문은 non-physical 상호작용에 중점.
- non-physical 예: 따라가기, 기분 표현, 미리 정의된 행동
- human-human demonstrations를 사용하지 않음.
즉, 사람-사람 상호작용 행동을 모방하는게 아니라 운영자의 컨트롤러를 통해 행동을 수집
physical interaction 기반의 협업 작업에 집중하는것이 아닌 미리 준비된 행동들을 operator가 제어함
III. BACKGROUND DIFFUSION MODELS
Diffusion Models란?
- 복잡한 데이터 분포를 모델링하기에 적합한 생성 모델(generative model)의 한 종류.
- 이미지, 영상, 모션 시퀀스 등 다양한 분야에서 활용됨
구성: 두 가지 과정으로 구성됨
1. Forward Process (순방향 과정)
- Langevin dynamics를 이산화(discretization)한 형태.
- 데이터 샘플 $( x_0 )$에 점점 더 많은 가우시안 노이즈 $( \epsilon_t )$ 를 추가하여 $( x_t )$ 생성
$$x_t = \sqrt{1 - \beta_t} \cdot x_{t-1} + \sqrt{\beta_t} \cdot \epsilon_t,\quad \epsilon_t \sim \mathcal{N}(0, I)$$
2. Backward Process (역방향 과정)
- 노이즈가 섞인 $( x_t )$ 로부터 점차 원래의 샘플 $( x_0 )$ 을 복원(denoise)함.
- 이 역방향 분포는 신경망 $( p_\theta(x_{t-1} | x_t) )$ 로 모델링됨.
해당 논문의 학습 방법
- 기존 diffusion model과 마찬가지로 신경망이 깨끗한 샘플 $( \hat{x}_0 )$을 직접 예측하도록 학습.
- 논문에서는 MDM [16]의 방식처럼 denoising step에서 $( \hat{x}_0 )$을 바로 출력.
또한 조건부 확산 모델(conditional diffusion models)에서는 확률 분포가 조건 신호 c에 의해 확장되어, $p_\theta(x_0 | x_t, c)$ 형태가 된다.
추론 시에는 무작위로 샘플링된 가우시안 노이즈와 조건 신호를 바탕으로 모델이 다양한 출력을 생성할 수 있다.
IV. PROBLEM SETTING
🎯 입력 및 목표
입력
- 프레임 길이 $( M )$만큼의 사람의 포즈 시퀀스 $( p \in \mathbb{R}^{M \times 7} )$
- 프레임 길이 $( M )$만큼의 로봇의 포즈 시퀀스 $( r \in \mathbb{R}^{M \times 7} )$
- 각 포즈는 3D 위치 + 4D 쿼터니언 회전으로 구성됨
- 3차원 위치 (position): $(x,y,z)$
- 4차원 회전 (orientation as quaternions): $(q_x, q_y, q_z, q_w)$
목표
이후 프레임 $( N )$ 에 대한 연속적인 operator commands 예측
- $( x_{1:N} \in \mathbb{R}^{N \times j} )$ (여기서 $( j )$ 는 프레임당 명령의 수)
🎮 예측할 두 가지 유형의 명령
- 연속 명령 (Continuous commands)
- gamepad의 조이스틱 입력
- 이산 명령 (Discrete events)
- 버튼 클릭으로 트리거되는 동작
- 두 종류로 나뉨:
- $( d_b )$: 특정 행동 (예: 점프, 춤 등) 실행
- $( d_m )$: 로봇의 모드 (예: 걷기 / 서기)
🧩 예측 시 구조
- 하나의 prediction window 내에서는
- 연속 명령은 프레임 단위로 시퀀스 전체 예측
- 이산 명령은 윈도우 단위로 1개씩만 예측
⚙️ 실행 구조
- 예측된 연속 + 이산 명령은 로봇의 motion control module로 전달됨
- → 해당 모듈이 실제 로봇을 제어함
표기법 참고
- $( x_t )$: diffusion step (노이즈 단계)에서의 입력
- 위 첨자(super script): 시퀀스 내 순서
- 아래 첨자(sub script): diffusion 단계

[Fig. 3. Overview of our method architecture.]
- 우리는 human poses history와 command history의 형태로 conditions를 사용합니다 (yellow).
- diffusion 모델은 robot 모델을 제어하기 위한 operator commands을 예측합니다 (blue).
- transformer는 또한 다양한 behavior와 mode에 대한 이산적인 예측을 출력합니다 (red).
- → 파란색은 Continuous commands, 빨간색은 Discrete events(걷기와 서기)
V. METHOD
우리 프레임워크는 두 가지 주요 구성요소로 이루어져 있습니다:
- human-robot interaction data collection
- a model to train autonomous interactions
A. Human-Robot Interaction Data Collection
우리의 데이터 캡처 환경은 Fig. 2에 나타나 있으며,
‘로봇’, ‘로봇을 조작하는 운영자’, 그리고 ‘로봇과 상호작용하는 사람’이 포함된다.
- 수집 대상 데이터:
- 사람의 포즈 $( p )$
- 로봇의 포즈 $( r )$
- 연속 명령 $( x )$ (joystick 등)
- 이산 명령 $( d_b )$, $( d_m )$ (버튼 기반 이벤트)
- 명령 데이터 기록 방식:
- 운영자 명령은 입력 장치(게임패드)로부터 직접 기록
- 포즈 데이터 캡처 장비:
- OptiTrack motion capture system 사용 [47]
- 마커 부착 위치:
- 로봇 본체
- 사람의 모자에 마커 부착
- 데이터 수집 방식:
- 전문가 운영자가 로봇을 직접 조작
- 사람의 포즈에 반응하는 행동을 수행함
- 예: 사람 따라가기, 감정 표현
- 감정 표현 예시:
- shy (부끄러움):
- 사람과 상호작용 시 로봇이 고개를 숙임
- angry (화남):
- 사람이 다가올 때 로봇이 고개를 흔들며 상호작용 거부
- shy (부끄러움):
- 데이터 구성:
- 운영자는 1명
- 상호작용하는 사람은 2명, 순차적으로 로봇과 상호작용
- 자세한 감정 목록 및 데이터 구성은 Tab. I 참조

B. Method Architecture
우리의 모델 아키텍처는 Fig. 3에 나타나 있다.
우리는 시뮬레이션에서 캐릭터 제어를 위한 CAMDM 프레임워크 [15]에서 영감을 받아,
실제 환경에서의 인간-로봇 상호작용을 위한 프레임워크를 제안한다.
인간-로봇 상호작용의 여러 과제를 해결하기 위해, 우리는 아키텍처에 도메인 특화적인 여러 조정과 확장을 기여한다.
우리 모델은 Transformer 백본 구조를 가지며, 여러 구성 요소를 조건(conditioning)으로 사용한다:
- 사람의 포즈 history $( c_p )$, 운영자 명령 history $( c_x )$, 그리고 diffusion 단계 $( t )$.
- 사람의 포즈 history $( c_p )$를 모델에 전달하기 전에, 로봇의 포즈 history $( r )$을 이용해 이를 로봇 기준 좌표계로 변환한다.
요약하면, 우리 모델 $( \mathcal{G} )$는 다음과 같이 정의된다:
- $(\hat{x}_0, \mathbf{d}_b, \mathbf{d}_m) = \mathcal{G}(\mathbf{c}_p, \mathbf{c}_x, t, \mathbf{x}_t, \mathbf{q}_b, \mathbf{q}_m)$
1) Diffusion을 통한 연속 명령 예측
연속적인 운영자 명령을 예측하기 위해 우리는 Diffusion Model을 사용한다.
- 보다 구체적으로, 학습 중에는 깨끗한 데이터 샘플 $( x_0 )$를 노이즈화하여 $( x_t )$로 만들고,
- 이를 다시 denoising step을 거쳐 깨끗한 신호 $( \hat{x}_0 )$로 복원하는 과정을 반복한다.
CAMDM [15] 와 공통점
우리는 CAMDM [15]에서 제안된 바와 같이 조건 토큰 분리(separation of conditioning tokens)와 과거 명령에 대한 classifier-free guidance를 적용한다.
CAMDM [15] 와 차이점
하지만 [15]와는 달리, 우리는 positional encoding에 dropout을 적용할 경우 출력이 노이즈화된다는 것을 발견했기 때문에, 우리 모델에서는 이를 채택하지 않았다.
또한, 우리의 조건 입력은 특정 상황(예: 사람이 로봇 가까이에 위치한 경우)에는 거의 0에 가까울 수 있다.
따라서 우리는 CAMDM [15]에서처럼 원시 조건(raw condition)에 마스킹을 적용하는 대신, encoding layer 이후에 마스킹을 적용하는 방식을 제안한다.
그렇지 않으면 모델이 zero-masking을 실제 0 값 조건으로 혼동할 수 있기 때문이다.
사람마다 키가 다르기 때문에, 우리는 훈련 중 사람 포즈 데이터에 중력 방향으로 ±0.3m의 임의 offset을 더해 데이터 다양성을 확보하는 데이터 증강(data augmentation)을 수행한다.
2) 이산 이벤트 예측
Diffusion 과정 내에서 연속 신호와 이산 신호를 함께 다루는 것은 간단하지 않다.
이에 우리는 이산 이벤트 예측을 Transformer 모델의 보조 작업(auxiliary tasks)으로 추가하는 방식을 제안한다.
구체적으로, 우리는 Transformer 아키텍처에 다음과 같은 분류용 쿼리 토큰(classification query tokens)을 추가한다:
- $( q_b )$: 이산 행동(discrete behavior)을 위한 토큰
- $( q_m )$: 모드 전환(mode)을 위한 토큰
Transformer 인코더의 출력은 각각의 분류 헤드(classification head)를 통해 다음을 예측한다:
- 모드 $( d_m )$
- 미리 정의된 이산 행동 $( d_b )$
모델은 여러 행동 클래스들 중에서 하나를 선택하거나,
기본 클래스(default class) (즉, 아무런 이산 이벤트가 발생하지 않는 경우)를 선택하도록 학습된다.
이러한 예측은 동일한 Transformer 인코더를 사용하지만, Diffusion 과정은 적용되지 않는다.
이 분류 헤드들을 훈련시키기 위해, 우리는 이산 이벤트의 발생 빈도와 기본 클래스 사이의 데이터 불균형을 고려해 가중치가 적용된 교차 엔트로피 손실(weighted cross-entropy loss)을 사용한다.
[CAMDM 참고]
https://arxiv.org/pdf/2404.15121
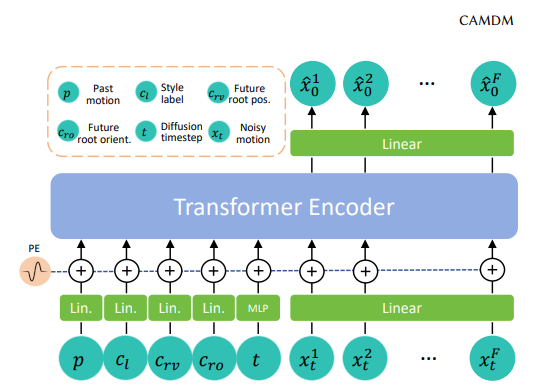
- Transformer 인코더 역할:
- diffusion 단계 $t$에서 조건 입력(conditioning input)을 생성.
- 이 조건은 이후 디코딩(denoising) 과정에서 사용됨.
- 디코딩 구성: 연속 명령과 이산 명령 예측
- 연속 명령 $x$ 예측
- MDM [16]과 유사한 방식 사용.
- 노이즈가 포함된 시퀀스 $x_t$를 입력으로 받아,
- 노이즈 없는 예측 시퀀스 $\hat{x}_0$를 직접 출력.
- $\hat{x}_0$는 reverse process에 의해 최종 샘플로 변환됨.
- 이산 명령 $d_b$, $d_m$ 예측
- 각 prediction window의 마지막 위치에 special token 삽입.
- 이 토큰은 Transformer 인코더를 통해 인코딩됨.
- 해당 위치의 출력을 통해 이산 명령을 분류(classification) 방식으로 예측.
- 연속 명령과 이산 명령을 동일한 구조에서 함께 처리할 수 있음.
- 연속 명령 $x$ 예측
- 전체 구조의 특징:
- 단일 Transformer 인코더를 통해 연속 및 이산 명령 모두 처리 가능.
- 시간적 연속성과 조건 기반 반응을 모두 반영 가능.
- 실제 환경에서 자율적이고 반응적인 로봇 제어에 적합한 효율적 아키텍처.
VI. EXPERIMENTS
섹션 VI-A에서는 우리가 실험에 사용한 로봇 플랫폼을 설명하고,
섹션 VI-B에서는 모델 파라미터와 실행 시간(runtime)에 대한 구현 세부 정보를 제공한다.
섹션 VI-C에서는 시뮬레이션 환경에서 실험을 수행하고,
섹션 VI-D에서는 실제 환경에서 사용자 연구(user study)를 수행하며,
섹션 VI-E에서는 서로 다른 로봇에 대한 zero-shot transfer 실험을 보여준다.
A. Robotic Platform
- 기반 플랫폼:
- Grandia et al. [4]이 개발한 플랫폼을 기반으로 구축됨.
- 해당 연구는 엔터테인먼트 응용을 위한 새로운 이족보행 캐릭터 디자인과 제어 방식을 제안함.
- 제어 아키텍처:
- 강화학습(reinforcement learning) 기반 제어 구조 사용.
- 연속 및 이산 명령 신호에 따라 **예술적인 동작(artistic motions)**을 안정적으로 모방할 수 있음.
- 런타임 동작:
- 명령 신호는 사용자 입력과 사전 정의된 애니메이션 콘텐츠를 융합하는 애니메이션 엔진에 의해 생성됨.
- 손에 들고 조작할 수 있는 운영자 컨트롤러 위에 직관적인 인터페이스가 구현되어, 로봇을 사용한 실시간 퍼포먼스 연출이 가능함.
- 로봇 사양:
- 키: 0.66 m
- 무게: 15.4 kg
- 각 다리 당 5자유도(DoF)
- 목에 4자유도(DoF)
- 쇼 기능 구성 요소:
- 작동하는 안테나 1쌍
- 조명이 들어오는 눈
- 헤드램프(headlamp)
- 스테레오 스피커 (몸체와 머리에 각각 한 쌍씩 위치)
- 기능 특징:
- 위의 구성 요소들은 로봇의 감정 상태를 표현하는 데 활용됨.
- 이들은 애니메이션 엔진으로부터의 신호와 로봇 상태 피드백을 기반으로, 로봇의 움직임과 동기화된 방식으로 작동함.
- 자세한 기술 설명:
- 보다 자세한 설명은 참고문헌 [4]를 참조할 것.
B. Implementation Details (추가 내용)
우리의 Transformer 인코더는 다음과 같은 구조를 가진다:
- latent dimension: 128
- feedforward 크기: 256
- attention head 수: 2개
- layers 수: 2개
우리는 총 5000 epoch 동안 학습을 수행했으며, 배치 크기는 128이고 learning rate는 1e-4로 설정하였다.
입력 시퀀스로는 15 frames의 past window를 사용하고, 25 future frames를 예측한다 (Sec. IV의 M과 N에 해당).
Diffusion 단계 수는 8로 설정하였다.
우리는 다음과 같은 출력을 예측한다:
- continuous signals 10개
- 최대 8개의 이산 행동 (기분 상태에 따라 달라짐)
- 2개의 모드 (걷기, 서기)
신호 품질 향상을 위해, 모델의 예측 결과를 로봇에 전달하기 전에 simple Gaussian smoothing filter를 적용하였다.
이 처리는 모션 캡처 기반 조건 입력에서 발생하는 노이즈를 줄이는 데 도움이 된다.
모든 연산(diffusion model, motion control policy, state estimation, animation engine 포함)은 로봇의 온보드 컴퓨터에서 실행된다.
사람의 포즈 정보와 autonomous operator 명령은 50Hz로 모델에 전달된다.
모델이 예측한 운영자 명령은 애니메이션 엔진(Sec. VI-A 참고)으로 전달되며,
이 엔진은 명령과 애니메이션 콘텐츠를 융합하여 제어 정책(control policy)에 보낸다.
이 low-level control policy는 actuator setpoint commands를 출력하며,
이 명령은 600Hz로 보간(interpolation)되어 액추에이터의 PD 컨트롤러로 전송된다.
원격 조작 명령 외에도, 이 low-level policy은 로봇의 고유감각(proprioceptive) 상태 입력도 함께 수신한다.
C. 시뮬레이션 기반 평가 (Simulation-Based Evaluation)
시뮬레이션 환경에서 자연스럽고 몰입감 있는 상호작용을 정량화하는 것은 어렵다.
이는 일반적인 로봇 제어 휴리스틱을 정의하거나, 학습 행동을 위한 보상 신호를 설정하는 것만큼이나 도전적인 일이다.
그럼에도 불구하고 아키텍처 선택을 측정하고 비교하기 위해, 우리는 모델 성능을 평가할 수 있는 다음과 같은 지표들을 정의한다:
- Facing Angle Error (FAE):(기본 모드에서는 로봇이 사람을 바라보는 것이 이상적이라 가정함)
- 로봇의 전방 방향과 로봇 루트에서 사람까지의 벡터 간의 평균 각도(도 단위)를 측정한다.
- Tracking Error (TE):(로봇이 사람을 가깝게 따라가는 것을 전제로 함)
- x-y 평면에서 로봇과 사람 사이의 평균 거리(오차)를 측정한다.
- Mean Squared Derivative (MSD):이는 예측된 결과의 노이즈 또는 prediction window 간의 급작스러운 전환을 식별하는 데 도움이 된다.
- 모든 연속 신호에 대해 평균을 낸다.
- 연속 신호들이 얼마나 급격하게 변화하는지를 측정한다.
우리는 제안한 접근법을 기본 transformer 모델과 비교하고, 아키텍처 구성 요소들에 대한 ablation study를 수행하였다.
시뮬레이션 실험에서는 전체 데이터 중 75%를 학습, 25%를 테스트 세트로 사용하며, 기본 모드에서 진행되었다.
평가 시에는 테스트 세트에 있는 사람의 동작을 재생하고, 시뮬레이션으로부터 사람 기준의 포즈를 스트리밍하여 모델에 입력한 뒤 모델이 로봇을 제어하게 한다.
또한 Fig. 5에서 보여주듯, 고정된 사람 포즈와 하나의 초기 로봇 포즈를 주면,
우리 모델은 다양한 출력(행동)을 생성할 수 있음을 정성적으로 확인할 수 있다.

1) 베이스라인 비교 (Baseline Comparison)
- 베이스라인 모델은 사람 포즈를 입력으로 받아 운영자 명령을 출력하는 결정론적(deterministic) 모델이다.
- 동일한 transformer 아키텍처를 사용하지만 diffusion 과정은 제거한다.
- 순차적인 출력을 고려하기 위해 query token을 입력에 추가한다.
Tab. II (상단)에서 볼 수 있듯이,
우리 모델은 사람을 더 잘 추적하며 (더 낮은 FAE 및 TE),
예측 창 간 전환도 더 부드럽고 신호 품질도 더 좋다 (더 낮은 MSD 점수).
이는 diffusion 모델을 사용하는 것이 단순 transformer보다 더 유리함을 보여준다.
2) Ablation 실험
아키텍처의 구성 요소들을 ablation 하기 위해, 다음과 같은 모델 변형들을 훈련시켰다:
- 사람 포즈 이력 제거: w/o human
- 명령 이력 제거: w/o commands
- dropout 제거: w/o dropout
또한 예측 window 길이가 결과에 미치는 영향을 확인하기 위해, 25, 50, 75 프레임 길이의 window를 실험하였다.
결과는 Tab. II에 제시되어 있다.

- 예측에 사람 포즈 정보가 없는 경우, tracking error가 매우 높게 나타남.
- 명령 이력을 조건에서 제거한 경우, 사람 추적 성능은 가장 높지만,
- 이전 예측과의 일관성을 유지하지 않아 신호가 불안정하고 prediction window 간 전환이 급격해짐 (MSD = 14.8).
- 우리의 최종 모델 (Ours, 25 frames)은 사람을 가까이 추적하는 성능과 신호의 일관성 사이에서 균형을 이룸.
- window 길이 비교 결과:
- 25 프레임일 때, diffusion 과정의 계산량을 고려했을 때실시간에 가까운 성능과 가장 우수한 추적 성능을 보임.
참고로, window 길이 외의 모든 ablation 실험은 25프레임 설정을 기준으로 훈련되었다.
D. 실제 환경 평가 (Real-World Evaluation)
우리는 실제 환경에서의 정성적(qualitative) 및 정량적(quantitative) 평가를 수행하였다.
정성적 결과는 Fig. 4 및 첨부된 영상에서 확인할 수 있다.
실험 평가의 목적은 다음 두 가지 질문에 답하는 것이다:
- 우리의 모델이 훈련된 운영자가 제어하는 것과 유사한 상호작용을 제공할 수 있는가?
- 로봇이 인간이 인식할 수 있을 정도로 다양한 감정 상태(mood)를 표현할 수 있는가?
이 질문들을 분석하기 위해 우리는 2단계로 구성된 직접 참여형 사용자 연구(user study)를 설계하였다.
사용자 연구는 총 20명의 참가자를 대상으로 진행되었으며, 참가자의 나이는 22세에서 44세 사이였고
평균 연령은 30세 (표준편차 4.8), 성별은 남성 12명, 여성 8명이었다.
참가자들은 우리 기관 소속이었으나, 본 프로젝트에 참여하지 않았고 로봇과 상호작용한 경험도 없었다.
상호작용 세션 이후, 참가자들은 간단한 정성적 설문지를 작성하였다.
1) 설문지 결과 (Questionnaire)
익명 설문지는 총 세 개의 진술(statement)로 구성되어 있다.
참가자들은 각 진술에 대해 1점(전혀 동의하지 않음)에서 5점(매우 동의함)까지의 5점 척도로 답하였다.
- 첫 번째 문항:→ 평균 점수: 2.2 (표준편차: 1.0)
- → 대부분의 참가자들은 로봇과의 상호작용 경험이 많지 않음을 의미함
- “나는 로봇과 상호작용한 경험이 있다”
- 두 번째 문항:→ 평균 점수: 4.9 (표준편차: 0.3)
- “상호작용이 몰입감 있고 즐거웠다”
- 세 번째 문항:→ 평균 점수: 4.7 (표준편차: 0.5)
- “로봇이 내 행동에 반응하고 있다는 느낌이 들었다”
→ 이 결과는 참가자들이 로봇과의 상호작용을 즐겁게 느꼈고, 로봇이 자신에게 반응하고 있다고 느꼈음을 보여준다.
2) 운영자 인식 테스트 (Operator Recognition)
이 실험에서는 각 참가자가 두 가지 설정 중 하나를 경험하는 절차를 따른다.
- 첫 번째 설정:
- 운영자가 기본 모드(default mode)에서 로봇을 제어하며, 감정 표현 없이 사람을 따라가는 행동을 수행함.
- 두 번째 설정:
- 우리 모델이 동일한 행동을 수행하도록 로봇을 제어함.
각 설정은 30초간 시연되며, 참가자는 이를 본 후 로봇을 제어한 것이 모델인지 운영자인지를 추측해야 한다.
각 참가자에게 **총 4번의 시연(각 설정 2번씩)**이 무작위 순서로 제공된다.
편향을 방지하기 위해, 자율 모드에서도 운영자가 실제로 조작하는 것처럼 연기하였다.
결과는 Tab. III의 confusion matrix로 보고되며,
행(row)은 실제 제어 방식(Ground Truth, GT),
열(column)은 사용자가 추측한 제어 방식(User)을 의미한다.
결과는 다음과 같다:
- 운영자가 제어한 설정은 55%의 정확도로 맞추어졌고,
- 우리 모델이 제어한 설정은 54%의 정확도로 맞추어졌다.
- 즉, 자율 모델은 46%의 확률로 운영자로 오인되었고,
- 운영자는 45%의 확률로 자율 모델로 오인되었다.
이 결과는 참가자들이 두 설정을 구분하기 어렵다는 것을 나타내며,
우리 모델이 기본 모드에서 전문가 수준의 운영자와 유사한 제어 능력을 보인다는 점을 시사한다.
단, 세 명의 참가자는 로봇에 익숙한 경험자였고,
이들은 두 모델을 구분하는 요령(trick)을 알아차릴 수 있었다.
예를 들어,
- 시야 밖(mocap 공간 경계)에서 사람이 사라질 경우,
- 운영자는 바로 따라가지만,
- 모델은 시야 안으로 들어올 때까지 기다렸다가 반응하는 차이를 관찰한 것이다.
3) 감정 인식 (Mood Recognition)
로봇이 우리 접근 방식으로 감정(mood)을 표현할 수 있는지를 확인하기 위해,
우리는 사람들에게 **네 가지 감정 상태(happy, sad, angry, shy)**를 보여주었다.
(자세한 설명은 Tab. I 참고)
- 감정의 순서는 참가자마다 무작위로 설정하였고,
- 각 참가자는 로봇과 1분간 상호작용한 후,
- 강제 선택(forced-choice) 방식으로 감정을 추측하게 하였다.
감정에 대한 설명은 따로 제공하지 않고,
단지 감정 이름만 사용자에게 알려주었다.
외부 요인의 영향을 최소화하기 위해,
이 실험에서는 감정마다 다르게 설정되어 있던 **눈 색상(colored eyes)**을 사용하지 않고,
**중립적인 눈 색상(neutral eye coloring)**을 적용하였다 (Fig. 4 비교).
- **결과는 Tab. IV의 혼동 행렬(confusion matrix)**로 보고되며,
- 행(row): 실제 감정 상태 (GT),
- 열(column): 사용자가 추측한 감정 상태 (User)
일반적으로 참가자들은 제시된 감정을 68%~74%의 정확도로 맞추었다.
하지만 혼동된 경우들(confusion cases)은 감정 인식에 대한 흥미로운 통찰을 제공한다:
- Angry(화남) 감정은 **Happy(기쁨)**으로 인식된 비율이 **26%**였는데,
- 이는 '동의하지 않는 몸짓(body shaking in disagreement)' 같은 이산 행동이
- 흥분을 나타내는 흔들림(shaking for excitement)으로 받아들여졌기 때문이다.
- (영상 35초 참고)
- 반대로, Happy(기쁨) 감정은 일부 참가자에게 **Angry(화남)**로 인식되었는데 (11%),
- 이는 로봇이 사람을 향해 달려가는 행동이
- 공격적인 “돌진(charge)” 동작처럼 보였기 때문이다.
- (영상 1분 45초 참고)
- Sad(슬픔) 감정은 **Shy(부끄러움)**으로 잘못 분류된 비율이 **21%**였으며,
- 이는 로봇이 주로 바닥을 바라보는 행동 때문이었다.
이러한 결과는 사용자들이 감정을 신뢰할 수 있는 수준으로 구별할 수 있음을 보여주며,
혼동된 사례에도 합리적인 해석이 가능함을 시사한다.
또한 감정들 사이에는 명확한 경계가 존재하지 않으며,
동일한 행동이라도 사람마다 다르게 해석될 수 있다는 점을 보여준다.
E. 제로샷 이종 플랫폼 간 전이 (Zero-Shot Cross-Embodiment Transfer)
우리의 방법이 다양한 로봇 플랫폼에 적용 가능함을 보여주기 위해,
우리는 제로샷(Zero-Shot) 전이를 사람형 로봇(humanoid robot)으로 수행하였다.
중요한 점은, 두 로봇 플랫폼 간에 **인터페이스 매핑(interface mapping)**이 유지된다는 것이다.
즉, 동일한 조이스틱으로 두 로봇 모두의 걷는 방향과 속도를 제어할 수 있도록 설정하였다.
Fig. 6 및 추가 영상에서는,
기본 동작들(예: 사람 추적, 방향 전환, 뒤로 걷기 등 – Tab. I 참고)이
다른 로봇 플랫폼에서도 성공적으로 전이되는 모습을 정성적으로 확인할 수 있다.
특히 주목할 점은,
우리 모델의 학습에 사용된 데이터는 전부 Sec. VI-A에서 소개된 로봇을 사용해 수집된 것이며,
그럼에도 불구하고 학습된 제어 능력이 다른 형태의 로봇으로도 자연스럽게 적용된다는 것이다.
VII. DISCUSSION
우리의 접근 방식은 자율적인 인간-로봇 상호작용을 향한 한 걸음을 내딛었지만, 여전히 여러 가지 한계가 존재한다.
가장 큰 한계는 robot-relative human pose를 감지하기 위해 모션 캡처 시스템에 의존하고 있다는 점이다.
앞으로는 실제 환경에서도 활용할 수 있도록 **시각 인식(perception)**을 통합하는 것을 목표로 하고 있다.
전역 인간 포즈(global human pose)를 추정하는 것을 넘어서,
향후 연구에서는 전신 포즈(full-body human pose) 또는 **얼굴 표정(facial expressions)**까지 예측하는 기능을 추가하여 더 섬세한 상호작용을 가능하게 할 수 있다.
예를 들어, 본 연구에서는 다양한 감정 상태(mood)를 수동으로 트리거하였지만,
앞으로는 세부적인 사람의 상태를 조건으로 하여 감정 변화를 자동으로 예측하는 단일 모델을 탐색하는 것이 유망한 방향이다.
또한, 우리는 **장기 의존성(long-term dependencies)**이나
**고차원적 의사결정(high-level decision-making)**이 필요한 복잡한 행동은 모델링하지 않았다.
예: 의미적으로 서로 다른 여러 상호작용을 하나의 일관된 상호작용으로 연결하는 경우 등.
대신, 우리는 사람의 포즈에 반응하거나 감정을 표현하는 등,
짧고 단순한 상호작용에 대해 인간 운영자와 유사한 성능을 달성하는 것에 초점을 맞추었다.
보다 복잡한 행동을 다루기 위해서는,
여러 상호작용을 연결할 수 있는 고차원적 의사결정 모듈을 통합하는 방향의 후속 연구가 필요하다.
우리의 데이터는 1명의 운영자와 2명의 사람을 대상으로 수집되었다.
사용자 연구를 통해, 사람마다 로봇과 상호작용하는 방식에 큰 다양성이 있음을 확인할 수 있었다.
더 많은 참가자를 포함한 데이터셋 확장은
- 다양한 인간 행동에 대한 모델의 강인성(robustness) 향상,
- 예측 가능한 상호작용의 다양성 증가에 기여할 수 있다.
향후 연구에서는 **물리적 접촉(physical contact)**이 포함된 상호작용도 탐색할 수 있다.
또한, 현재 상호작용은 1대의 로봇과 1명의 사람에 한정되어 있으나,
향후 연구에서는 이를 다수의 로봇과 다수의 사람이 참여하는 상호작용으로 확장하는 것도 매우 흥미로운 방향이 될 것이다.
VIII. CONCLUSION
우리는 인간의 포즈를 운영자 명령(operator commands)으로 매핑하는 학습 방식을 기반으로,
자율적인 인간-로봇 상호작용을 가능하게 하는 방법을 제안하였다.
이 방법은 diffusion 기반 접근 방식을 사용하여,
**연속 명령(continuous commands)**과 **이산 버튼 입력(discrete button presses)**을 모두 예측한다.
또한, 액추에이터 명령이 아닌 운영자 명령을 사용함으로써
40분 미만의 데이터만으로 모델을 학습시킬 수 있어,
데이터 요구량을 획기적으로 줄였다.
우리의 접근 방식은 안전성 측면에서도 유리한데,
이는 운영자 인터페이스가 일반적으로 **내재된 안전 보장(safety guarantees)**을 갖도록 설계되어 있기 때문이다.
마지막으로, 우리의 실험 결과는 다음을 보여준다:
- 사용자들이 시스템과의 상호작용을 즐겁게 경험했으며,
- 다양한 감정 상태를 신뢰할 수 있는 수준으로 인식할 수 있었고,
- 자율 제어된 로봇과 운영자가 제어한 로봇을 구분하기 어려워했다는 점에서, 제안된 모델이 단순한 상호작용에 있어 운영자 수준의 성능을 달성했음을 시사한다.
'Paper Review' 카테고리의 다른 글
| LLM3: Large Language Model-based Task and Motion Planningwith Motion Failure Reasoning (0) | 2025.02.27 |
|---|---|
| SNN의 약점을 개선해 나가고 있는 방법들 (0) | 2024.09.14 |
| [논문리뷰] SpikingResformer 및 코드 실행 (0) | 2024.09.12 |
| [SpikeFormer 논문리뷰] SPIKFORMER: WHEN SPIKING NEURAL NETWORK MEETS TRANSFORMER (0) | 2024.08.22 |
| Neural Transformation Learning for Deep Anomaly Detection Beyond Images (0) | 2024.05.17 |
Contents
소중한 공감 감사합니다