로봇,ROS,SLAM
OpenVLA Tutorial 3
- -
OpenVLA 테스트를 위해 LIBERO 데이터셋을 불러보자.
먼저 OpenVLA 환경설치 후
https://github.com/openvla/openvla
GitHub - openvla/openvla: OpenVLA: An open-source vision-language-action model for robotic manipulation.
OpenVLA: An open-source vision-language-action model for robotic manipulation. - openvla/openvla
github.com
https://github.com/openvla/openvla?tab=readme-ov-file#libero-setup
GitHub - openvla/openvla: OpenVLA: An open-source vision-language-action model for robotic manipulation.
OpenVLA: An open-source vision-language-action model for robotic manipulation. - openvla/openvla
github.com
리베로 설치하고 실험하면 무조건 오류가 나는데
pip install robosuite==1.4
위와 같이 robosuite를 1.4 버전으로 맞춰주면 잘 작동한다 (이거 찾는데 3시간 걸렸다 ㅠㅠ 창피하네유)
# ["libero_spatial", "libero_object", "libero_goal", "libero_10"]
task_suite_name = "libero_10" # can also choose libero_spatial, libero_object, etc.
task_id = 0
resize = 256
benchmark_dict = benchmark.get_benchmark_dict()
task_suite = benchmark_dict[task_suite_name]()
# retrieve a specific task
task = task_suite.get_task(task_id)
task_name = task.name
task_description = task.language
task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
print(f"[info] retrieving task {task_id} from suite {task_suite_name}, the " + \
f"language instruction is {task_description}, and the bddl file is {task_bddl_file}")
# step over the environment
env_args = {
"bddl_file_name": task_bddl_file,
"camera_heights": resize,
"camera_widths": resize
}
env = OffScreenRenderEnv(**env_args)
env.seed(0)
env.reset()
init_states = task_suite.get_task_init_states(task_id) # for benchmarking purpose, we fix the a set of initial states
env.set_init_state(init_states[0])
dummy_action = [0.] * 7
replay_images = []
if task_suite_name == "libero_spatial":
max_steps = 220 # longest training demo has 193 steps
elif task_suite_name == "libero_object":
max_steps = 280 # longest training demo has 254 steps
elif task_suite_name == "libero_goal":
max_steps = 300 # longest training demo has 270 steps
elif task_suite_name == "libero_10":
max_steps = 520 # longest training demo has 505 steps
elif task_suite_name == "libero_90":
max_steps = 400 # longest training demo has 373 steps
for step in range(max_steps):
obs, reward, done, info = env.step(dummy_action)
img = obs["agentview_image"]
img = img[::-1, ::-1]
replay_images.append(img)
env.close()
그러고 시각화를 하면
mediapy.show_video(replay_images, fps=10, codec='gif')
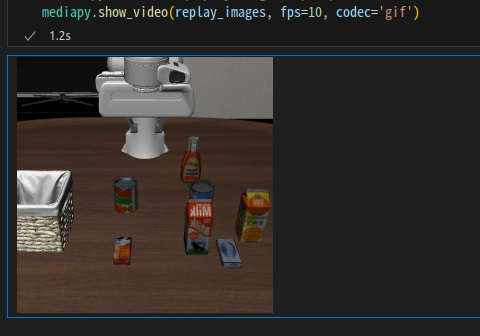
움직이는게 보인다.
자 그러면 OpenVLA를 작동시켜 보자.
openvla root 위치에 01.test.ipynb 파일을 만든다.
필요한 라이브러리들을 불러 온다.
from typing import Optional, Union
from pathlib import Path
import os
import mediapy
import tqdm
import numpy as np
필요한 함수들을 불러 온다.
from experiments.robot.robot_utils import (
DATE_TIME,
get_action,
get_model,
invert_gripper_action,
normalize_gripper_action,
set_seed_everywhere,
)
from experiments.robot.openvla_utils import get_processor
from experiments.robot.libero.libero_utils import (
get_libero_image,
quat2axisangle,
)
옵션 클래스를 정한다.
class GenerateConfig:
# fmt: off
#################################################################################################################
# Model-specific parameters
#################################################################################################################
model_family: str = "openvla" # Model family
pretrained_checkpoint: Union[str, Path] = "" # Pretrained checkpoint path
load_in_8bit: bool = False # (For OpenVLA only) Load with 8-bit quantization
load_in_4bit: bool = False # (For OpenVLA only) Load with 4-bit quantization
center_crop: bool = True # Center crop? (if trained w/ random crop image aug)
#################################################################################################################
# LIBERO environment-specific parameters
#################################################################################################################
task_suite_name: str = "libero_spatial" # Task suite. Options: libero_spatial, libero_object, libero_goal, libero_10, libero_90
num_steps_wait: int = 10 # Number of steps to wait for objects to stabilize in sim
num_trials_per_task: int = 50 # Number of rollouts per task
#################################################################################################################
# Utils
#################################################################################################################
run_id_note: Optional[str] = None # Extra note to add in run ID for logging
local_log_dir: str = "./experiments/logs" # Local directory for eval logs
use_wandb: bool = False # Whether to also log results in Weights & Biases
wandb_project: str = "YOUR_WANDB_PROJECT" # Name of W&B project to log to (use default!)
wandb_entity: str = "YOUR_WANDB_ENTITY" # Name of entity to log under
seed: int = 7 # Random Seed (for reproducibility)
# fmt: on
cfg = GenerateConfig()
# ["libero_spatial", "libero_object", "libero_goal", "libero_10"]
cfg.task_suite_name = "libero_10" # can also choose libero_spatial, libero_object, etc.
cfg.pretrained_checkpoint = f"openvla/openvla-7b-finetuned-libero-10"
cfg.load_in_4bit = True
resize_size = 512
# [OpenVLA] Set action un-normalization key
cfg.unnorm_key = cfg.task_suite_name
# Set random seed
set_seed_everywhere(cfg.seed)
model = get_model(cfg)
# [OpenVLA] Check that the model contains the action un-normalization key
if cfg.model_family == "openvla":
# In some cases, the key must be manually modified (e.g. after training on a modified version of the dataset
# with the suffix "_no_noops" in the dataset name)
if cfg.unnorm_key not in model.norm_stats and f"{cfg.unnorm_key}_no_noops" in model.norm_stats:
cfg.unnorm_key = f"{cfg.unnorm_key}_no_noops"
cfg.unnorm_key
# [OpenVLA] Get Hugging Face processor
processor = None
if cfg.model_family == "openvla":
processor = get_processor(cfg)
리베로 라이브러리 임포트
from libero.libero import benchmark
from libero.libero.envs import OffScreenRenderEnv
from libero.libero import get_libero_path
def get_libero_env(task, resolution=256):
"""Initializes and returns the LIBERO environment, along with the task description."""
task_description = task.language
task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
env_args = {"bddl_file_name": task_bddl_file, "camera_heights": resolution, "camera_widths": resolution}
env = OffScreenRenderEnv(**env_args)
env.seed(0) # IMPORTANT: seed seems to affect object positions even when using fixed initial state
return env, task_description
# Initialize LIBERO task suite
benchmark_dict = benchmark.get_benchmark_dict()
task_suite = benchmark_dict[cfg.task_suite_name]()
num_tasks_in_suite = task_suite.n_tasks
print(f"Task suite: {cfg.task_suite_name}")
[info] using task orders [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Task suite: libero_10
task_id = 4
# Get task
task = task_suite.get_task(task_id)
# Get default LIBERO initial states
initial_states = task_suite.get_task_init_states(task_id)
# Initialize LIBERO environment and task description
env, task_description = get_libero_env(task, resolution=256)
import imageio
def save_rollout_video(rollout_images, idx):
"""Saves an MP4 replay of an episode."""
mp4_path = f"./demo_task_{idx}.mp4"
video_writer = imageio.get_writer(mp4_path, fps=30)
for img in rollout_images:
video_writer.append_data(img)
video_writer.close()
print(f"Saved rollout MP4 at path {mp4_path}")
return mp4_path
task_successes = 0
episode_idx = 0
print(f"\nTask: {task_description}")
# Reset environment
env.reset()
# Set initial states
obs = env.set_init_state(initial_states[episode_idx])
# Setup
t = 0
replay_images = []
if cfg.task_suite_name == "libero_spatial":
max_steps = 220*2 # longest training demo has 193 steps
elif cfg.task_suite_name == "libero_object":
max_steps = 280*2 # longest training demo has 254 steps
elif cfg.task_suite_name == "libero_goal":
max_steps = 300*2 # longest training demo has 270 steps
elif cfg.task_suite_name == "libero_10":
max_steps = 520*2 # longest training demo has 505 steps
elif cfg.task_suite_name == "libero_90":
max_steps = 400*2 # longest training demo has 373 steps
print(f"Starting task : {task}...")
while t < max_steps + cfg.num_steps_wait:
try:
# IMPORTANT: Do nothing for the first few timesteps because the simulator drops objects
# and we need to wait for them to fall
if t < cfg.num_steps_wait:
get_libero_dummy_action = [0, 0, 0, 0, 0, 0, -1]
obs, reward, done, info = env.step(get_libero_dummy_action)
t += 1
continue
# Get preprocessed image
img = get_libero_image(obs, resize_size)
# Save preprocessed image for replay video
replay_images.append(img)
# Prepare observations dict
# Note: OpenVLA does not take proprio state as input
observation = {
"full_image": img,
"state": np.concatenate(
(obs["robot0_eef_pos"], quat2axisangle(obs["robot0_eef_quat"]), obs["robot0_gripper_qpos"])
),
}
# Query model to get action
action = get_action(
cfg,
model,
observation,
task_description,
processor=processor,
)
# Normalize gripper action [0,1] -> [-1,+1] because the environment expects the latter
action = normalize_gripper_action(action, binarize=True)
# [OpenVLA] The dataloader flips the sign of the gripper action to align with other datasets
# (0 = close, 1 = open), so flip it back (-1 = open, +1 = close) before executing the action
if cfg.model_family == "openvla":
action = invert_gripper_action(action)
# Execute action in environment
obs, reward, done, info = env.step(action.tolist())
if done:
task_successes += 1
print('Success', task_successes)
break
t += 1
except Exception as e:
print(f"Caught exception: {e}")
break
# Save a replay video of the episode
save_rollout_video(replay_images, task_description)
mediapy.show_video(replay_images, fps=15, codec='gif')

굿
'로봇,ROS,SLAM' 카테고리의 다른 글
| [Genesis Part2] Genesis 다양한 예제 및 튜토리얼 돌려보기 - 로봇팔 (0) | 2025.01.01 |
|---|---|
| [Genesis Part1] Genesis 알아보고 Ubuntu에서 구동해보기 (0) | 2025.01.01 |
| OpenVLA Tutorial 2 (1) | 2024.11.19 |
| OpenVLA Tutorial 01 (1) | 2024.11.19 |
| Issac Sim 설치 and ROS URDF 불러오기 (2) | 2024.11.17 |
Contents
소중한 공감 감사합니다