Machine Learning
PEFT (LoRA와 QLoRA)에 대해서 알아보자 1부
- -
LLM을 그냥 쓰는 것에 대해
LLM은 일반적인 지식에는 강하지만, 특정 도메인에 대한 깊이 있는 전문성을 가지기는 어렵다는 한계를 보여준다.
그러므로 어떤 도메인이나 작업에 특화된 모델을 만들기 위해서는 기존의 사전 학습된 모델을 적절히 '조정'하여 사용해야 한다.
모델 조정의 대표적인 방법
- In-context Learning:
프롬프트 입력 시 관련 예시를 함께 제공.
이 방법에는 모델의 파라미터(가중치, 편향)는 업데이트되지 않음 - Full Fine-tuning:
모델의 모든 파라미터를 재학습하여 업데이트 함- 장점
적은 데이터로도 효과적인 학습 가능
정확도 향상 - 단점
높은 계산 비용
엄청난 GPU 메모리 요구량
급격한 망각 현상 (이전에 학습하였던 정보를 급격하게 잊어버리는 현상)
- 장점
- PEFT (Parameter Efficient Fine-tuning)
선택된 일부 파라미터만 학습하여 업데이트 함
PEFT (Parameter-Efficient Fine-Tuning)
주요 목적: 거대 언어 모델을 효율적으로 조정하여 필요한 리소스와 비용을 대폭 줄이는 기법
- 모델의 전체 파라미터 중 일부만 선택적으로 조정함으로써, 모델의 핵심 구조를 유지하고 특정 기능이나 작업에 맞게 조정할 수 있음
- 모델의 전체 파라미터를 업데이트하지 않기 때문에 많은 비용과 시간을 절약할 수 있음
주로 사용되는 기술
- Adapter Layers
- 모델의 기존 아키텍처 사이에 작은 신경망 층을 추가
- 학습 시 기존 파라미터는 고정되고, Adapter 레이어의 파라미터만 학습하므로 계산량을 줄일 수 있다.
- Prompt Tuning
- 특정 입력에 대한 응답을 조정함으로써, 모델이 새로운 작업을 수행할 수 있도록 한다.
- 이 방법은 모델의 전체 가중치를 변경하지 않고 입력 프롬프트에 해당하는 파라미터만을 학습한다
- 프롬프트 파라미터는 모델 전체 파라미터에 비해 훨씬 작기 때문에 학습시간이 단축된다.
- LoRA (Low-rank Adaptation)
- 모델의 가중치 행렬에 저차원 행렬을 적용하여, 원래의 가중치는 유지하면서 소수의 파라미터만 조정하는 방법
1. LoRA (Low-Rank Adaptation)
LoRA는 2023년 초에 Microsoft에서 발표한 PEFT 방법 중 하나로, 이후 가장 일반적으로 사용되고 있습니다.
LoRA는 Adapter 유형에 속하는 방법으로,
PLM의 기존 가중치는 고정 상태로 유지하면서, 학습이 가능한 저차원의 가중치 행렬을 추가하여 모델을 조정합니다.
새로 추가된 가중치 행렬 (LoRA 가중치)은 기존 가중치에 비해 훨씬 낮은 차원을 가지며, 파라미터 수를 크게 줄이면서도 모델의 성능을 유지하거나 향상시킬 수 있습니다.
LoRA의 구성 요소와 작동 원리
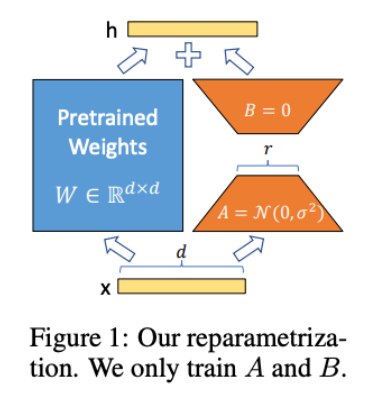
왼쪽의 파란색 모듈은 모델의 원래 가중치이고, 오른쪽의 주황색 모듈은 학습하려는 LoRA 가중치를 나타냅니다.
LoRA 학습 중에는
1. PLM의 원래 가중치(W, 왼쪽 파란색 모듈)는 고정되어 수정되지 않습니다.
2. 대신 새로운 행렬인 A 와 B 가 추가되며, 이 두 행렬은 다음과 같이 구성됩니다.
- A : d x r 차원의 행렬로, 여기서 d 는 원래 가중치 행렬 W 의 차원, r 은 분해 순위를 나타냅니다.
- B : r x d 차원의 행렬로, A 와 곱해져 원래 가중치 행렬 W 와 같은 d x d 크기의 행렬을 형성합니다.
이 두 행렬 A 와 B 의 곱은 원래 가중치 행렬 W 와 합산되어 최종 출력에 영향을 미치게 됩니다. 이 과정에서 r 의 크기는 매우 중요한데,
- r 이 작으면 학습되는 파라미터 수가 줄어들어 학습이 빠르고 비용 효율적이지만, 너무 작으면 모델의 성능이 제한될 수 있습니다.
- r 이 크면 더 복잡한 작업을 처리할 수 있지만, 학습 시간과 비용이 증가합니다.
2. QLoRA (Quantized LoRA)
QLoRA는 LoRA의 확장된 형태로, LoRA 기법에 새로운 형태의 양자화를 적용하여 메모리 사용과 계산량을 더욱 줄이는 방법입니다.
공통점과 차이점
공통점:
- 이 방법은 PLM의 가중치는 고정하고 LoRA 가중치만 학습하는 점에서 LoRA와 동일
차이점:
- PLM에 추가적인 양자화를 통해 모델을 더욱 경량화한다.
더보기

FP32 (32비트 부동소수점 표현)
보통 컴퓨터에서 실수를 표현할 때 사용하는 데이터 타입은 FP32입니다.
- 이 포맷은 1비트의 부호(sign), 8비트의 지수(exponent), 23비트의 가수(mantissa)로 구성
높은 정밀도를 제공하여 복잡한 계산과 민감한 데이터 처리에 적합하지만, 그만큼 메모리 사용량과 계산 요구량이 높습니다.
FP16 (16비트 부동소수점 표현)
FP16은 모델 경량화를 위해 가장 쉽게 사용할 수 있는 데이터 타입입니다.
- 이 포맷은 1비트의 부호, 5비트의 지수, 10비트의 가수로 구성
FP32에 비해 메모리 사용량과 계산 속도가 개선되어, 빠른 학습 및 추론이 가능합니다.
그러나 정밀도가 감소하므로, 일부 고정밀이 요구되는 계산에서는 부적합합니다.
메모리를 적게 사용하므로 딥러닝 분야에서 매우 인기가 있지만, 16비트의 정밀도가 낮아서 모델의 정확도가 떨어질 수 있다. 따라서 모델을 훈련할 때는 일반적으로 fp32를 사용하고 추론할때는 fp16을 사용하여 연산속도를 높이는 경우가 많다.
BF16 (16비트 부동소수점 포맷)
BF16은 구글에서 개발한 16비트 부동소수점 포맷으로,
- FP32와 동일한 8비트의 지수를 사용하지만 가수는 7비트만을 사용합니다.
이 포맷은 FP32와 유사한 범위의 값을 표현할 수 있으며, FP16보다 더 높은 정밀도를 제공하면서도 메모리와 계산 효율성은 FP16 수준을 유지합니다.
그러나 NVIDIA A100 등 최신 하드웨어에서만 지원되므로 제품 확인이 필요합니다.
INT8(8-bit integer)
8비트 정수 포맷으로, 부동소수점 대신 정수를 사용하여 데이터를 표현합니다.
메모리 요구량을 크게 줄이고 추론 속도를 빠르게 하지만, 낮은 정밀도를 제공하므로 일부 세밀한 정보가 손실될 수 있습니다.
4-bit NormalFloat (NF4)
4-bit NormalFloat은 가중치 값을 4비트로 양자화하는 기법입니다.
일반적으로 사용되는 32비트 부동소수점(32bit floating point, FP32) 표현 대신,
4비트를 사용함으로써 데이터를 표현하는 데 필요한 비트 수를 대폭 줄입니다.
NF4는 학습 시 고정되는 PLM 가중치에만 적용되고, 학습되는 LoRA 가중치는 BF16 포맷을 사용합니다.
그리고 학습이 완료되면 PLM과 LoRA의 출력을 합산할 때, PLM의 NF4는 BF16으로 역양자화됩니다.
Double Quantization
이중 양자화는 가중치를 양자화할 때 발생하는 양자화 상수와 같은 부가적인 파라미터를 한 번 더 양자화하는 기법입니다.
NF4로 양자화된 가중치를 한 번 더 양자화하는 것은 아니고,
가중치를 양자화할 때 발생하는 양자화 상수를 대상으로 양자화하여 메모리 공간을 더욱 줄이는 방법입니다.
Paged Optimization
Paged Optimization은 모델의 가중치를 페이지 단위로 분할하여 메모리를 최적화하는 기술입니다.
이 방식은 필요한 가중치만을 메모리에 동적으로 로딩하여 전체 메모리 사용량을 관리합니다.
특히, GPU 메모리가 부족할 경우 CPU RAM이나 디스크로 메모리 사용을 확장하여 GPU 메모리의 한계를 극복하고 OOM (Out of Memory) 상황을 방지할 수 있습니다.
https://hyundoil.tistory.com/401
PEFT (LoRA와 QLoRA)에 대해서 알아보자 2부, 실전 훈련
이번 포스팅에서는 PEFT 방법 중 가장 핵심이 되는 QLoRA에 대해 실제코드를 살펴보고 학습 결과를 확인해 보겠습니다. 1부 되짚어 보기지난 포스팅에서는 거대 언어 모델(LLM)을 조정하는 세 가
hyundoil.tistory.com
'Machine Learning' 카테고리의 다른 글
| PEFT (LoRA와 QLoRA)에 대해서 알아보자 2부, 실전 훈련 (2) | 2024.11.11 |
|---|---|
| [Modeling] Knowledge Distillation 알아보기 (3) | 2024.09.21 |
| 멀티모달 역량 및 경험을 쌓아보자 (1) | 2024.09.17 |
| 모델 경량화 (0) | 2024.09.14 |
| ViT 훈련 원리 요약, 질문에 대답하기 (1) | 2024.09.13 |
Contents
소중한 공감 감사합니다